from phasic import (
Graph, with_ipv, GaussPrior, HalfCauchyPrior,
ExpStepSize, ExpRegularization, clear_caches,
Adam, Adagrad, RMSprop, SGDMomentum,
SparseObservations, dense_to_sparse, is_sparse_observations,
) # ALWAYS import phasic first to set jax backend correctly
import numpy as np
import jax.numpy as jnp
import pandas as pd
from typing import Optional
import matplotlib.pyplot as plt
from matplotlib.colors import LogNorm
import seaborn as sns
%config InlineBackend.figure_format = 'svg'
from tqdm.auto import tqdm
from vscodenb import set_vscode_theme
np.random.seed(42)
set_vscode_theme()
sns.set_palette('tab10')Multi-feature inference
Rewards
We can fit to reward transformed observations, like the total branch length of the coalescent. In the example below, we sample total branch lengths from the model and pass them to svgd along with the appropriate rewards.
nr_samples = 4
@with_ipv([nr_samples]+[0]*(nr_samples-1))
def coalescent_1param(state):
transitions = []
for i in range(state.size):
for j in range(i, state.size):
same = int(i == j)
if same and state[i] < 2:
continue
if not same and (state[i] < 1 or state[j] < 1):
continue
new = state.copy()
new[i] -= 1
new[j] -= 1
new[i+j+1] += 1
transitions.append([new, [state[i]*(state[j]-same)/(1+same)]])
return transitions
true_theta = [7]
graph = Graph(coalescent_1param) # should check using the graph hash if a trace of the graph is cached or available online
graph.update_weights(true_theta)
graph.plot()
rewards = graph.states().T
rewards = np.sum(rewards, axis=0)
nr_observations = 10000
observed_data = graph.sample(nr_observations, rewards=rewards)
observed_dataarray([0.20881364, 0.22286545, 0.47727512, ..., 0.27287602, 0.27616 ,
0.86309785], shape=(10000,))prior = GaussPrior(ci=[5, 25])
step_size = ExpStepSize(first_step=0.05, last_step=0.01, tau=30.0)#graph.compute_trace()
svgd = graph.svgd(observed_data=observed_data,
rewards=rewards,
prior=prior,
# learning_rate=step_size
learning_rate=ExpStepSize(first_step=0.05, last_step=0.01, tau=30.0)
# optimizer=Adam(0.3),
)svgd.plot_trace() ;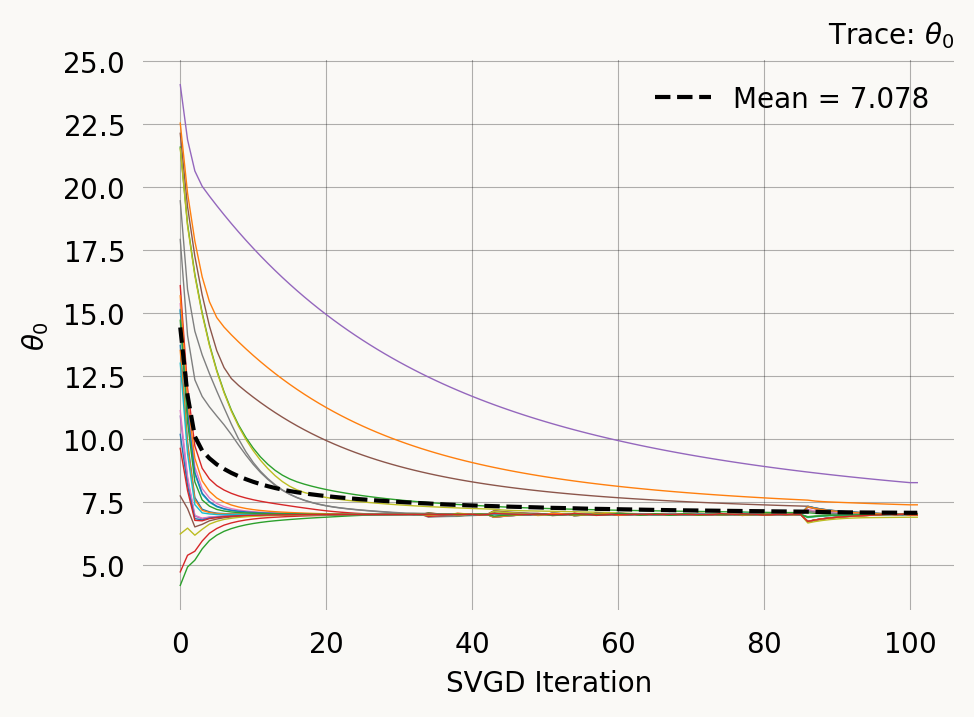
svgd.summary()Parameter Fixed MAP Mean SD HPD 95% lo HPD 95% hi
0 No 7.0143 7.0781 0.2625 6.9026 7.3945
Particles: 24, Iterations: 100svgd.get_results()["theta_mean"].item()7.078119882418123svgd.map_estimate_from_particles()([7.014289300415117], -1509.6312153875745)Multi-feature observations
Observations can be vectors of features, in which case you need to supply a set or rewards for each feature. The example below is the the same as above, except that we pass observations as single-value vectors.
# same as above
graph = Graph(coalescent_1param)
graph.update_weights(true_theta)
nr_observations = 10000
rewards = graph.states().T
rewards = np.sum(rewards, axis=0)
observed_data = graph.sample(nr_observations, rewards=rewards)
# make reward vector the only row of a 2d array
rewards = np.reshape(rewards, (-1, len(rewards)))
# reshape data into a single-column 2d array
observed_data = np.reshape(observed_data, (len(observed_data), -1))
# #graph.compute_trace()
# svgd = graph.svgd(observed_data=observed_data, rewards=rewards, **params)
# svgd.get_results()["theta_mean"].item()# svgd.map_estimate_from_particles()With more than one feature, SVGD computes the likelihood for each feature using the the provided rewards. In this example, sample 1’ton, 2’ton, and 3’ton branch lengths are first, second and third observation features. The reward matrix passed to svgd must have as many rows as your data has features. Three rows in the reward matrix:
graph = Graph(coalescent_1param)
graph.update_weights(true_theta)
rewards = graph.states().T
rewards = rewards[:-1]
rewardsarray([[0, 4, 2, 0, 1, 0],
[0, 0, 1, 2, 0, 0],
[0, 0, 0, 0, 1, 0]], dtype=int32)Data must be passed to svgd as a SparseData object. You can create it like this:
n = nr_observations
idxs = np.arange(rewards.shape[0])
feature_data = np.concatenate([graph.sample(n, rewards=rewards[i]) for i in idxs])
features = np.concatenate([[i]*n for i in idxs])
feature_slices = [(i*n, (i+1)*n) for i in idxs]
sparse_observations = SparseObservations(
values=observed_data,
features=features,
n_features=3,
slices=feature_slices
)
sparse_observationsSparseObservations(values=<10000 values>, n_features=<3, features=<10000 values>, slices=<10000 values>)It can also be created from a two-dimensional array where each row is an observation with all but a single non-nan value:
n = nr_observations
observed_data = np.zeros((n * (rewards.shape[0]), rewards.shape[0]), dtype=float)
observed_data[:] = np.nan
for i in range(rewards.shape[0]):
observed_data[(i*n):((i+1)*n), i] = graph.sample(n, rewards=rewards[i])
np.random.shuffle(observed_data)
observed_data[:nr_observations] # just the first nr_observations rows
observed_dataarray([[0.16902187, nan, nan],
[ nan, nan, 0. ],
[ nan, nan, 0. ],
...,
[0.06733945, nan, nan],
[0.06576532, nan, nan],
[ nan, 0.03887678, nan]], shape=(30000, 3))sparse_observations = dense_to_sparse(observed_data)
sparse_observationsSparseObservations(values=<30000 values>, n_features=<3, features=<30000 values>, slices=<30000 values>)graph = Graph(coalescent_1param)
svgd = graph.svgd(observed_data=sparse_observations,
rewards=rewards,
prior=GaussPrior(ci=[1, 20]),
n_iterations=200,
learning_rate=ExpStepSize(first_step=0.01, last_step=0.001, tau=30.0)
)
svgd.summary()
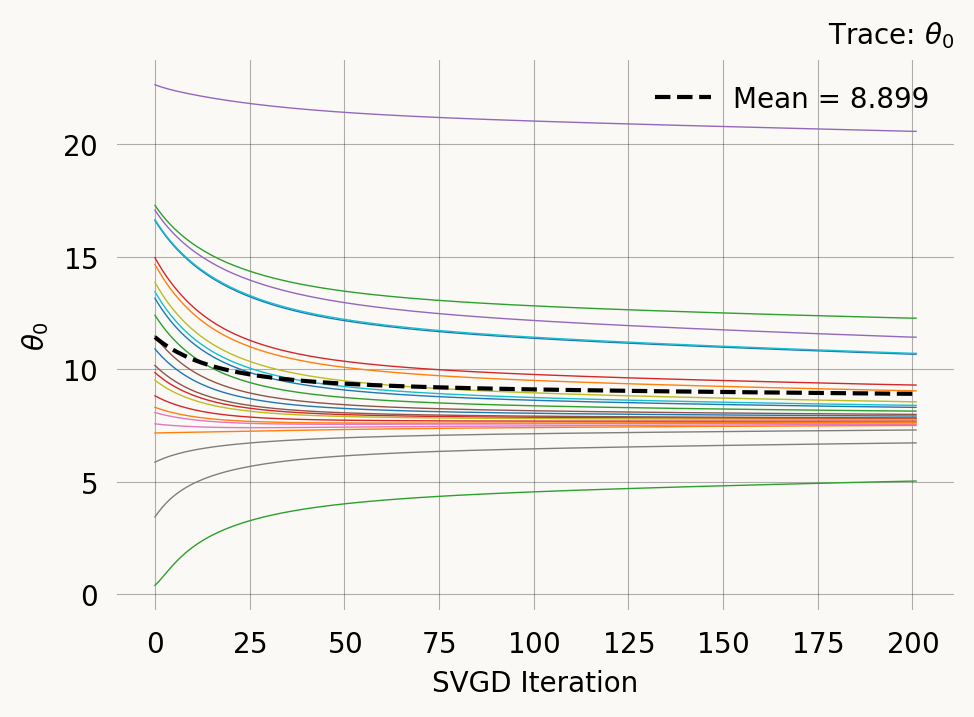
svgd.plot_convergence() ;Parameter Fixed MAP Mean SD HPD 95% lo HPD 95% hi
0 No 7.7968 8.8993 2.8740 5.0206 12.2642
Particles: 24, Iterations: 200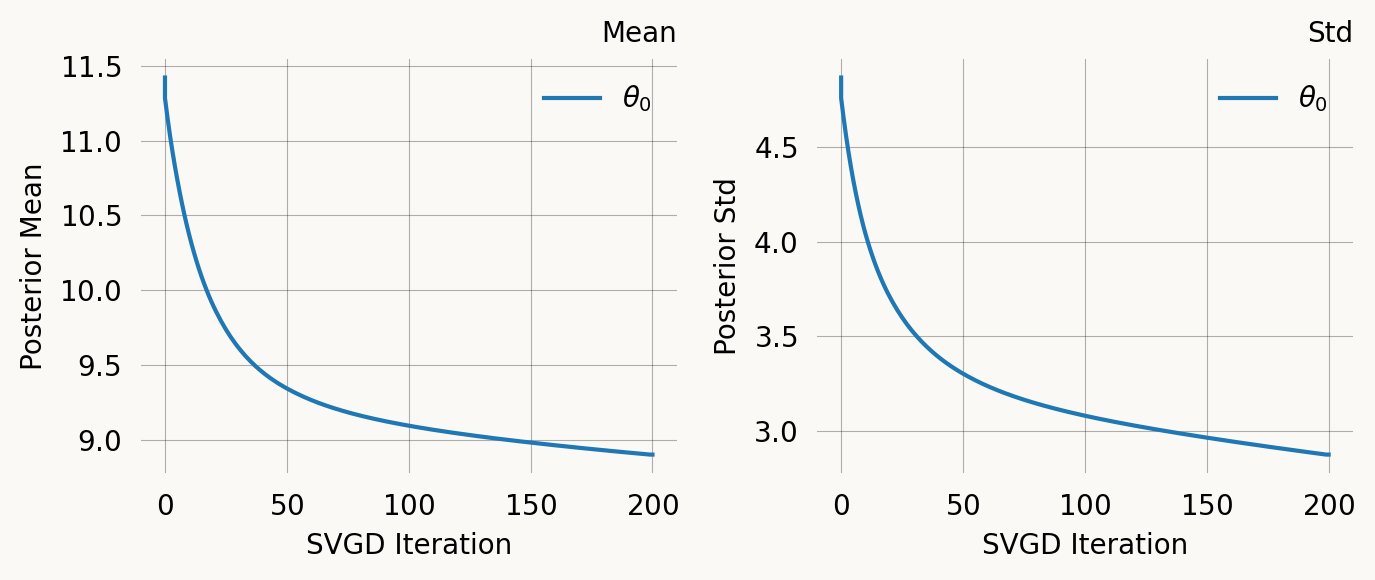
svgd.plot_trace()