This notebook provides a comprehensive reference for the prior distributions, step size schedules, and regularization schedules available in phasic for use with SVGD inference. Each class is demonstrated with its construction options, key parameters, and visual output.
from phasic import ( Graph, with_ipv,# Priors GaussPrior, HalfCauchyPrior, DataPrior,# Step size schedules ConstantStepSize, ExpStepSize, AdaptiveStepSize, WarmupExpStepSize,# Regularization schedules ConstantRegularization, ExpRegularization, ExponentialCDFRegularization,# Optimizers (for examples) Adam,) # ALWAYS import phasic first to set jax backend correctlyimport numpy as npimport jax.numpy as jnpimport matplotlib.pyplot as pltimport seaborn as snsnp.random.seed(42)try:from vscodenb import set_vscode_theme set_vscode_theme()exceptImportError:passsns.set_palette('tab10')
Overriding theme from NOTEBOOK_THEME environment variable. <phasic._DeviceListFilter object at 0x13a7c3e50>
Priors
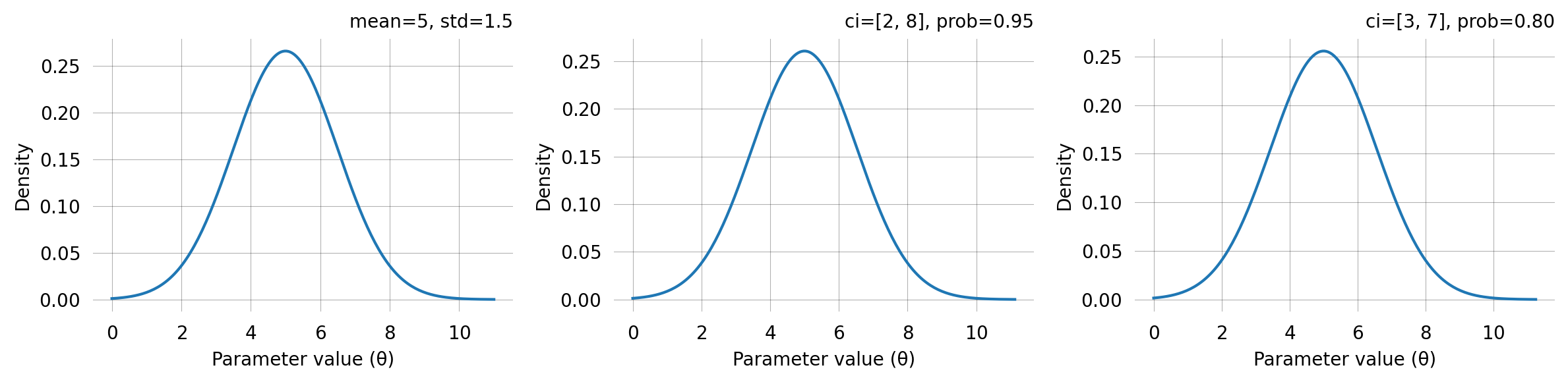
GaussPrior
A Gaussian (normal) prior centred on a point estimate with a given spread. It can be specified in two ways:
Mean and standard deviation — when you know the centre and spread directly.
Credible interval — when you can state a range that should contain the parameter with a given probability.
The two specifications are equivalent: a 95% credible interval [low, high] maps to mean = (low + high) / 2 and std = (high - low) / (2 * z_0.975).
The credible-interval specification is often the most intuitive: “I believe the parameter is between 2 and 8 with 95% probability” translates directly to GaussPrior(ci=(2, 8)).
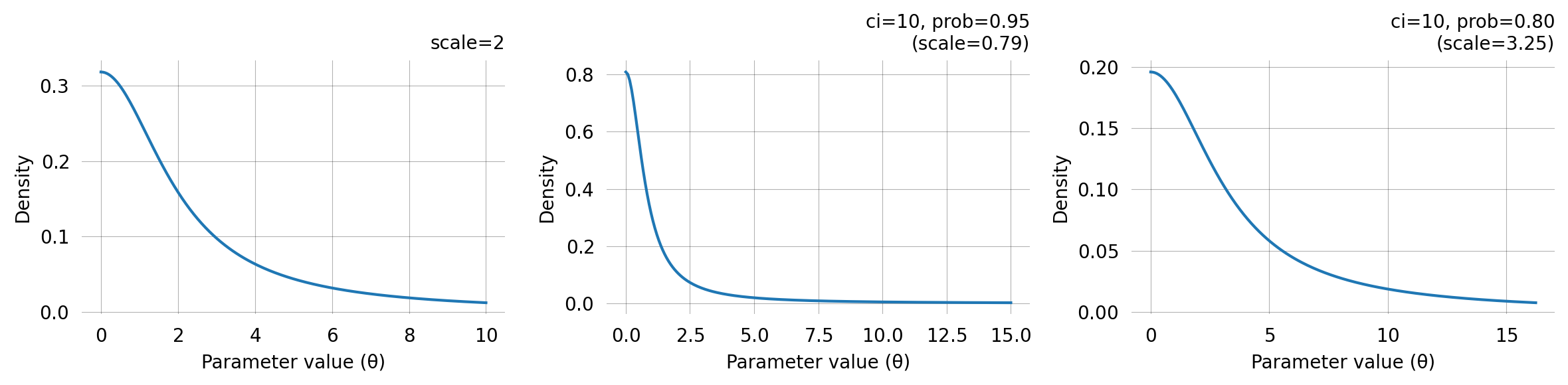
HalfCauchyPrior
A half-Cauchy prior with support on (0, \infty). Its heavy tails make it a popular weakly informative prior for scale and rate parameters — it concentrates mass near zero but allows for large values.
The CI specification says: “I believe there is a prob probability that the parameter is below ci.” A lower prob for the same ci implies a larger scale (heavier tail).
DataPrior
DataPrior constructs a data-informed prior automatically. Instead of specifying mean and spread by hand, it estimates them from the observed data using either method of moments (standard phase-type graphs) or probability matching (joint probability graphs). The graph type is detected automatically.
The result is a list of per-parameter GaussPrior objects (with None at fixed-parameter positions) that integrates directly with graph.svgd().
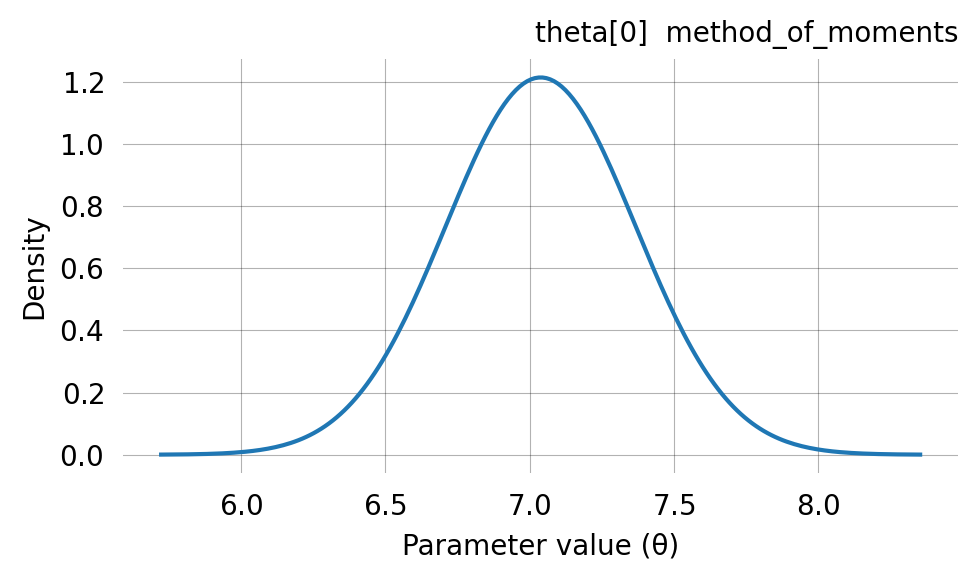
# Build a simple coalescent modelnr_samples =4@with_ipv([nr_samples]+[0]*(nr_samples-1))def coalescent_1param(state): transitions = []for i inrange(state.size):for j inrange(i, state.size): same =int(i == j)if same and state[i] <2:continueifnot same and (state[i] <1or state[j] <1):continue new = state.copy() new[i] -=1 new[j] -=1 new[i+j+1] +=1 transitions.append([new, [state[i]*(state[j]-same)/(1+same)]])return transitionsgraph = Graph(coalescent_1param)true_theta = [7.0]graph.update_weights(true_theta)data = graph.sample(1000)
DataPrior is iterable — you can inspect individual per-parameter priors and pass it directly to graph.svgd() as the prior argument:
# Inspect per-parameter priorsprint(f"Number of parameters: {len(dp)}")for i, p inenumerate(dp):if p isnotNone:print(f" theta[{i}]: GaussPrior(mean={p.mu:.3f}, std={p.sigma:.3f})")else:print(f" theta[{i}]: None (fixed)")
Number of parameters: 1
theta[0]: GaussPrior(mean=7.039, std=0.329)
# Use directly with SVGDsvgd = graph.svgd(data, prior=dp, optimizer=Adam(0.25))svgd.summary()
Parameter Fixed MAP Mean SD HPD 95% lo HPD 95% hi
0 No 7.0287 6.9786 0.1275 6.6600 7.0866
Particles: 24, Iterations: 100
DataPrior parameters:
Parameter
Type
Default
Description
graph
Graph
—
Parameterized graph
observed_data
array
—
Observed data
sd
float
2.0
Multiplier on the asymptotic standard error for the prior width
fixed
list
None
(index, value) tuples for fixed parameters
nr_moments
int
None
Number of moments (standard graphs only)
rewards
array
None
Reward vectors (standard graphs only)
theta_dim
int
None
Number of parameters (auto-detected)
theta_init
array
None
Initial guess for the free parameters
discrete
bool
None
Discrete or continuous model (auto-detected)
verbose
bool
False
Print progress
The sd parameter controls how wide the resulting Gaussian priors are relative to the estimation uncertainty. A larger value gives a more permissive prior:
sd=1: Tight prior, trusts the MoM estimate closely
sd=2 (default): Balanced
sd=3–5: Wide prior, uses MoM only as a rough guide
Per-parameter priors
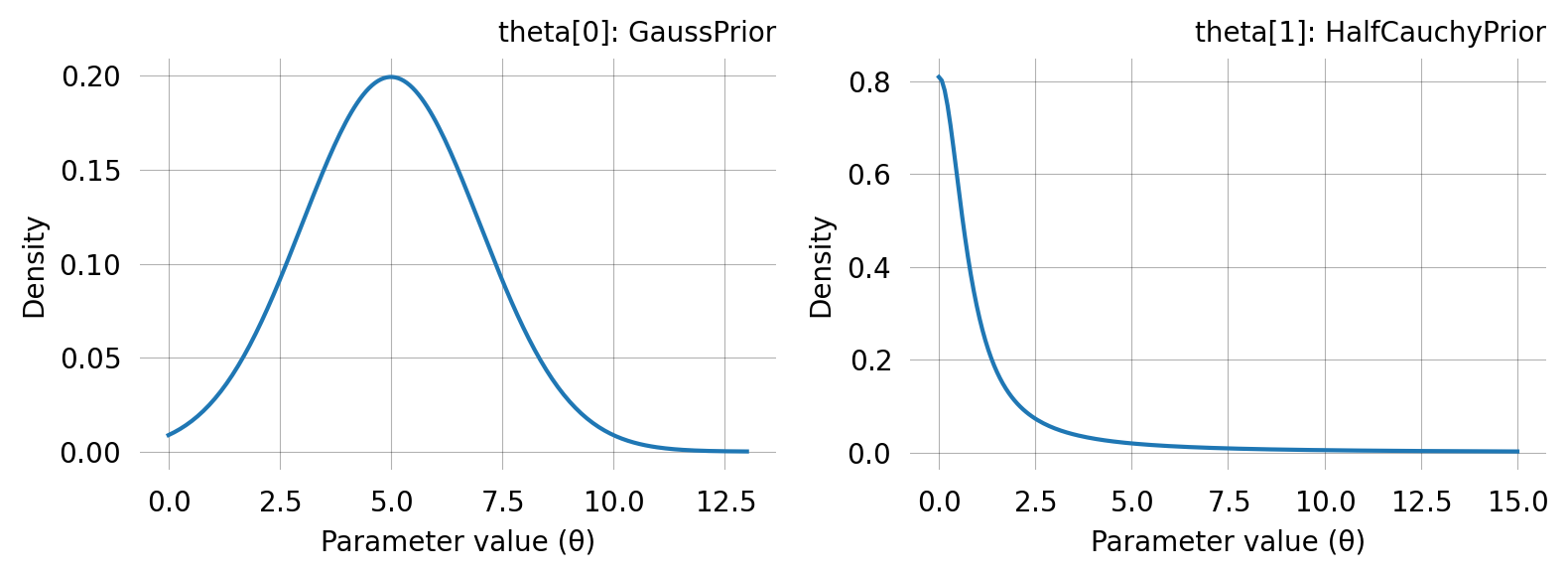
When a model has multiple parameters, you can assign a different prior to each one by passing a list of prior objects to graph.svgd(). Use None at positions corresponding to fixed parameters:
The step size (learning rate) controls how far particles move at each SVGD iteration. A step size that is too large causes oscillation; too small causes slow convergence. Schedules let you vary the step size over the course of optimisation.
Pass a schedule to graph.svgd() via the learning_rate parameter, or to an optimizer like Adam(learning_rate=schedule).
Class
Behaviour
ConstantStepSize
Fixed step size throughout
ExpStepSize
Exponential decay from a first to a last value
WarmupExpStepSize
Linear ramp-up then exponential decay
AdaptiveStepSize
Adjusts based on particle spread
ConstantStepSize
The simplest schedule: the same step size at every iteration. This is also the implicit default when you pass a plain number as the learning_rate.
const = ConstantStepSize(0.01)print(f"Step at iteration 0: {const(0)}")print(f"Step at iteration 500: {const(500)}")const.plot(200)
Step at iteration 0: 0.01
Step at iteration 500: 0.01
Parameter
Type
Default
Description
step_size
float
0.01
Fixed step size
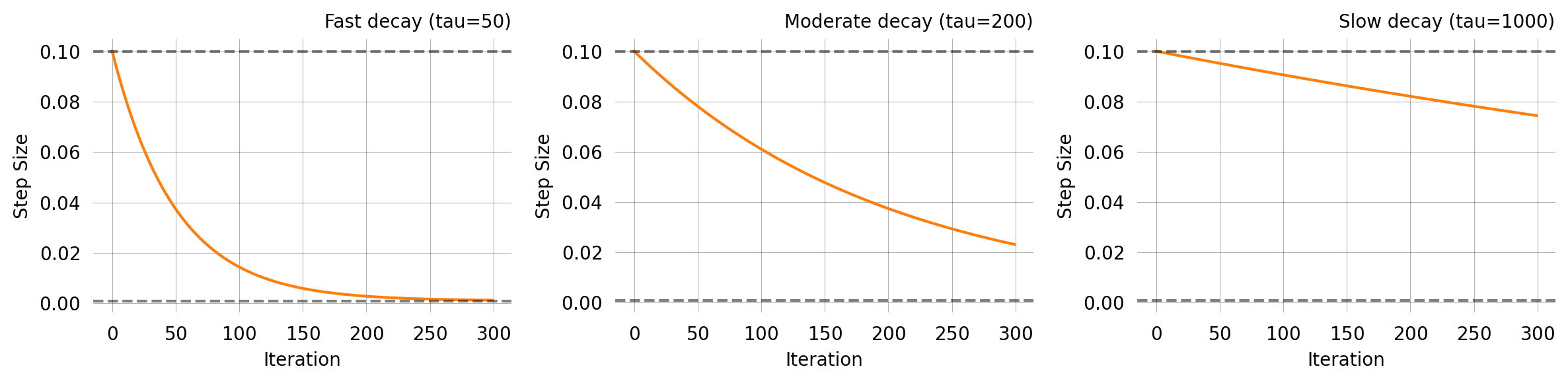
ExpStepSize
Exponential decay from first_step to last_step with time constant tau:
At t = \tau, roughly 63% of the decay has occurred. This is the most commonly used schedule — start with a large step to explore, then settle down for fine-tuning.
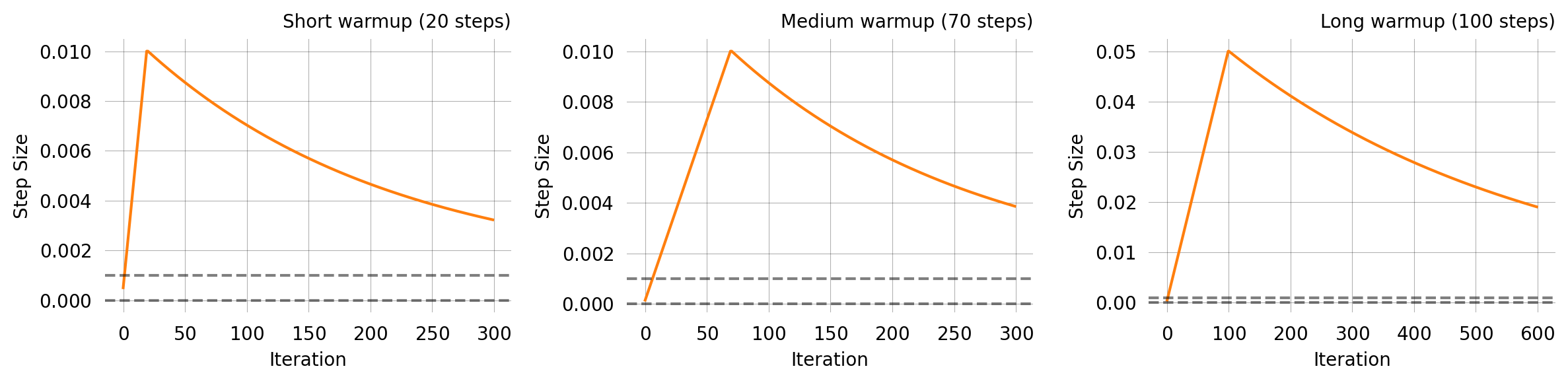
A linear ramp-up phase followed by exponential decay. This is useful with Adam and other adaptive optimizers where moment estimates are poorly calibrated in the first few iterations — a warmup prevents large early updates.
Adjusts the step size dynamically based on particle spread. When particles are too concentrated the step size increases; when too dispersed it decreases. This is a simple heuristic that does not require tuning a decay schedule, but its behaviour depends on the optimisation trajectory.
Base step: 0.01
Without particles: 0.0100
Concentrated particles: 0.0110 (increases)
Spread particles: 0.0099 (decreases)
Parameter
Type
Default
Description
base_step
float
0.01
Initial step size
kl_target
float
0.1
Target log-spread of particles
adjust_rate
float
0.1
Rate of multiplicative adjustment per step
Comparison
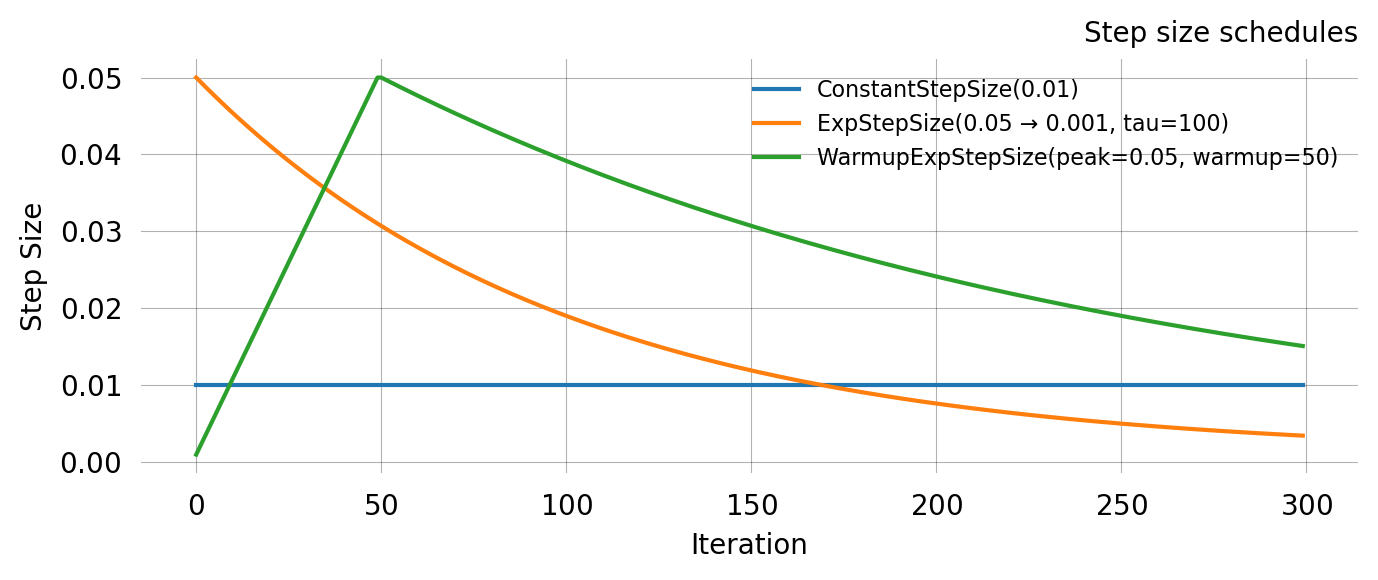
All four schedules on the same axes for a 300-iteration run:
nr_iter =300iters = np.arange(nr_iter)schedules = {'ConstantStepSize(0.01)': ConstantStepSize(0.01),'ExpStepSize(0.05 → 0.001, tau=100)': ExpStepSize(0.05, 0.001, 100.0),'WarmupExpStepSize(peak=0.05, warmup=50)': WarmupExpStepSize(0.05, 50, 0.001, 200.0),}fig, ax = plt.subplots(figsize=(7, 3))for label, sched in schedules.items(): vals = [float(sched(i)) for i in iters] ax.plot(iters, vals, label=label)ax.set_xlabel('Iteration')ax.set_ylabel('Step Size')ax.set_title('Step size schedules')ax.legend(fontsize=8)plt.tight_layout()
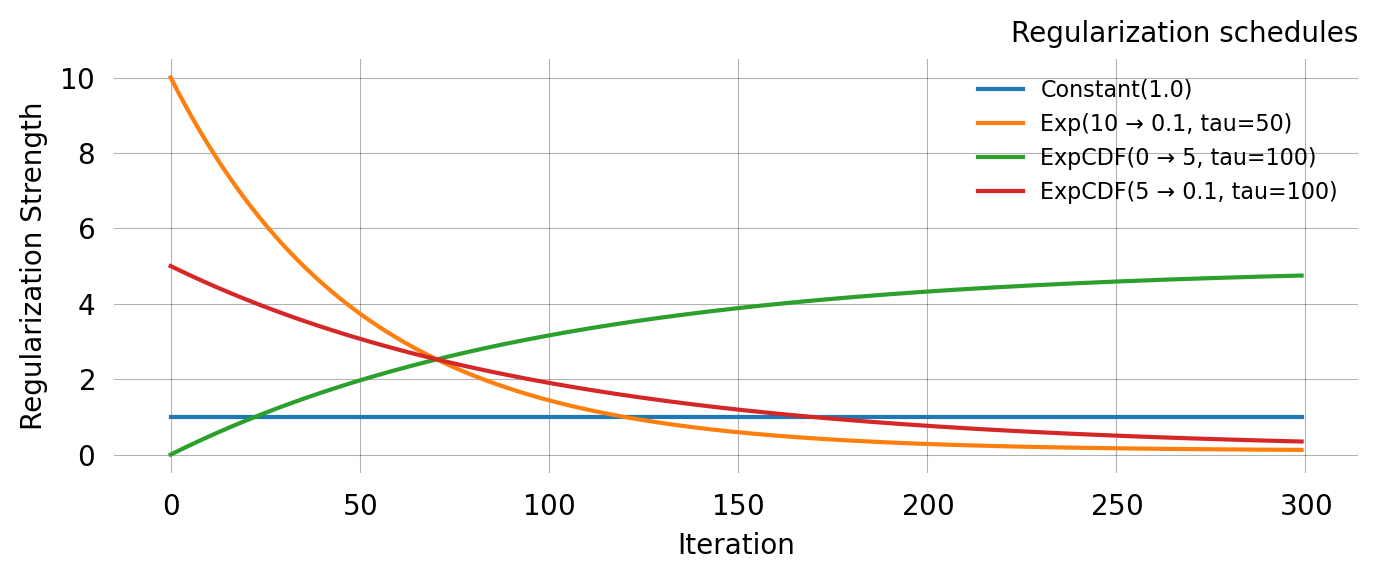
Regularization schedules
Moment regularization adds a penalty term to the SVGD objective that encourages the model moments at the current parameter values to match the empirical moments. This is controlled by the regularization parameter in graph.svgd() and requires specifying nr_moments.
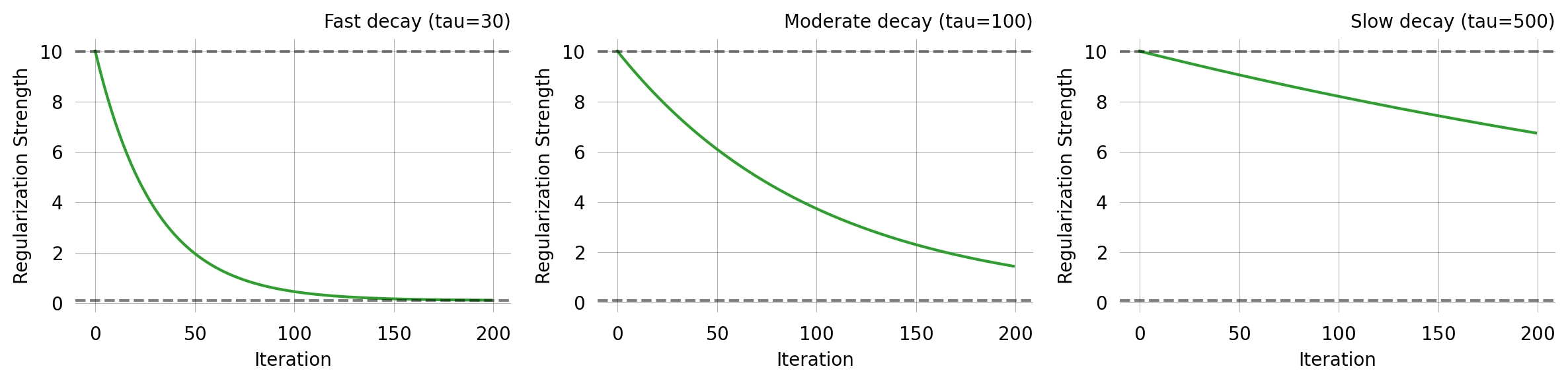
Strong regularization early in optimisation helps guide particles into a reasonable region; reducing it later lets the likelihood dominate for fine-tuning.
Class
Behaviour
ConstantRegularization
Fixed regularization strength
ExpRegularization
Exponential decay from first to last value
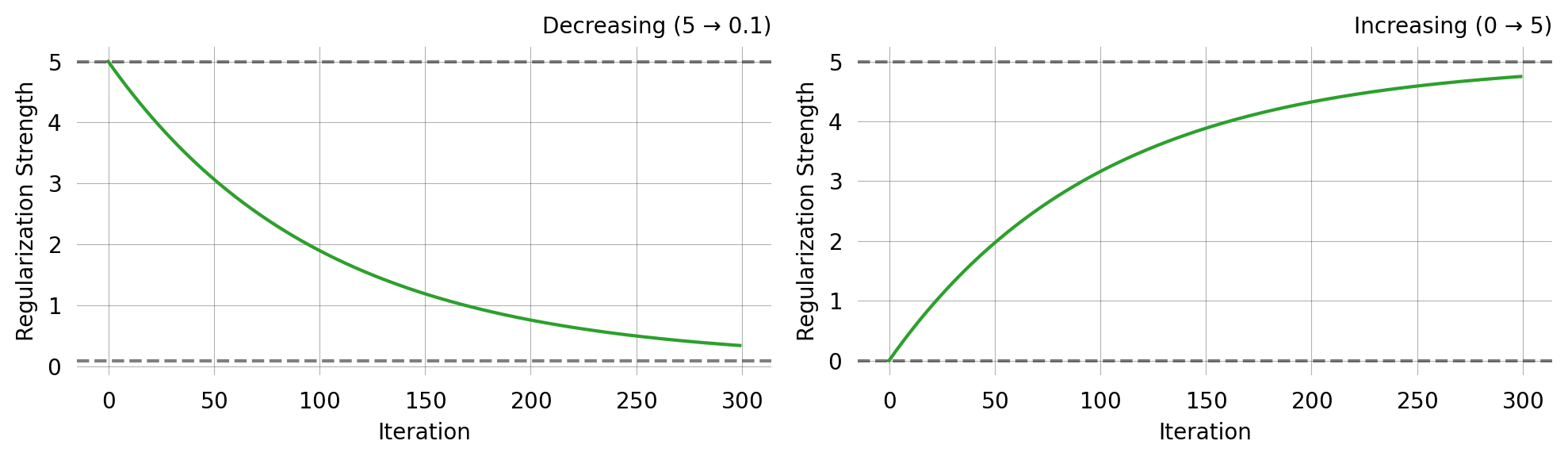
ExponentialCDFRegularization
Smooth CDF-based transition (works for both increasing and decreasing)
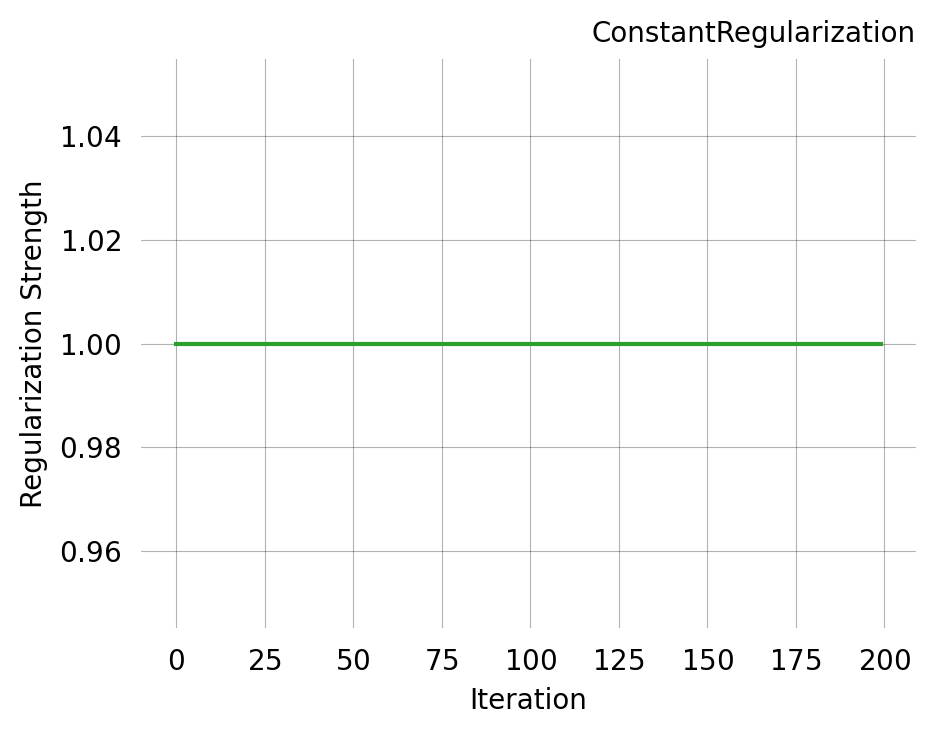
ConstantRegularization
A fixed regularization strength throughout optimisation.
const_reg = ConstantRegularization(1.0)print(f"Strength at iteration 0: {const_reg(0)}")print(f"Strength at iteration 500: {const_reg(500)}")const_reg.plot(200)
Strength at iteration 0: 1.0
Strength at iteration 500: 1.0
Parameter
Type
Default
Description
regularization
float
0.0
Fixed regularization strength
ExpRegularization
Exponential decay, identical in form to ExpStepSize:
This is mathematically equivalent to ExpRegularization for decreasing schedules, but the parameterisation makes it equally natural for increasing schedules — useful for progressive regularization where you start with pure likelihood and gradually add moment matching.
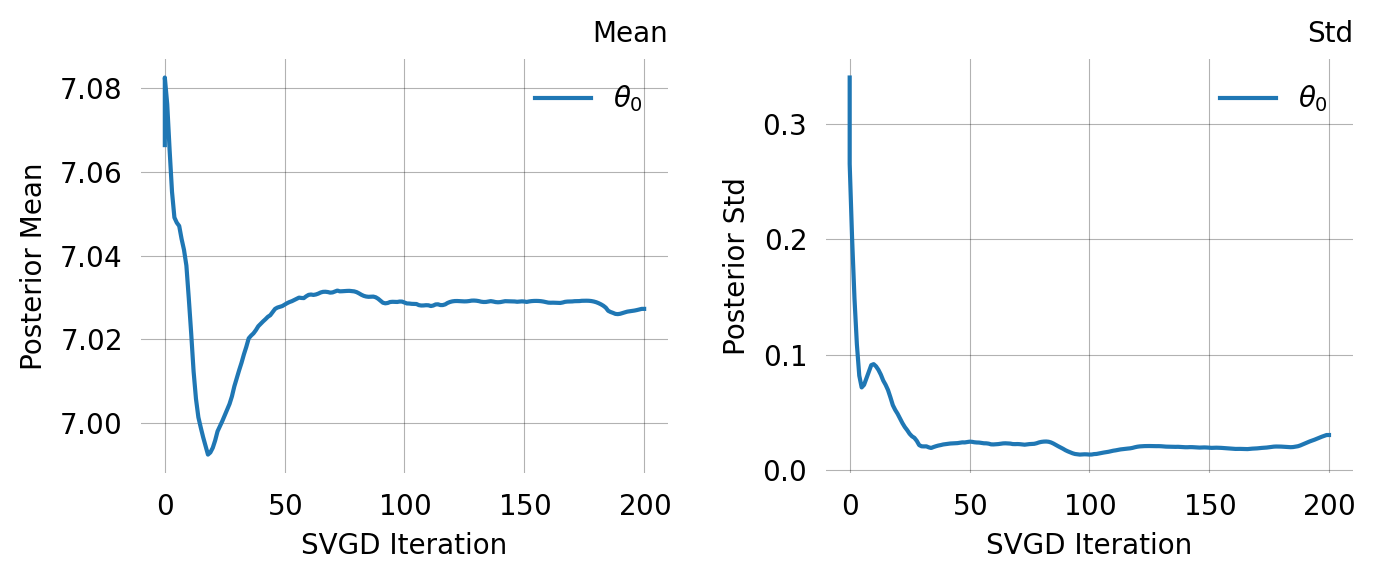
Parameter Fixed MAP Mean SD HPD 95% lo HPD 95% hi
0 No 7.0294 7.0273 0.0306 6.9664 7.1014
Particles: 24, Iterations: 200
TipGeneral guidance
Prior: Start with DataPrior for an automatic data-informed prior. Fall back to GaussPrior(ci=...) if you have domain knowledge, or HalfCauchyPrior for weakly informative priors on scale parameters.
Step size: Adam(0.25) with the default constant step size works well for many problems. If convergence is unsteady, try ExpStepSize or WarmupExpStepSize.
Regularization: Often not needed if the prior is informative. Use ExpRegularization to stabilise early iterations in difficult models.